You Can Get Crawled, Indexed, and Found. That Is Not the Same as Being Cited.
By Samar Pratap Singh · 17 min read · 16 June 2026
Something interesting appears when we look at how AI platforms handle the same query across different sources. Two websites on the same topic. Both technically accessible, both indexed, both with functional sitemaps and reasonable structured data. One gets cited in AI-generated answers with its exact language, its specific examples, its named observations. The other gets paraphrased into a vague generality, or not mentioned at all.
The difference is almost never in the technical setup. By the time you have sorted crawlability, sitemap structure, schema markup, and entity clarity, the technical foundations are largely in place. What differentiates citation from invisibility at that point is content. Specifically: whether the content gives an AI system something worth citing.
That is what this piece is about. It is also where this blog series ends.
Over four pieces we have covered the four foundational layers of the Zaillor AI Visibility Audit: structured data (helping AI systems interpret what your content means), robots.txt configuration (controlling which AI crawlers can reach which pages), sitemap structure (telling crawlers what to prioritise and how fresh it is), and brand entity clarity (establishing consistent, cross-referenced identity across the web). This fifth and final parameter is AI Content Optimisation: what the content itself needs to do once AI systems can reach it.
Get the first four right and AI crawlers arrive at your pages efficiently. They know who you are and that you are one consistent thing. What they find when they get there determines whether they cite you, paraphrase you, or move on.
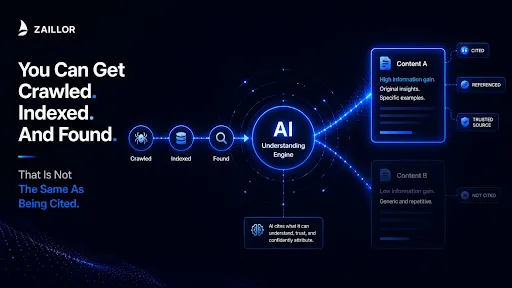
What AI Content Optimisation Actually Means
The phrase is easy to overcomplicate. At its core, AI content optimisation is the practice of writing content that is easy for AI systems to understand, accurately extract, confidently summarise, and comfortably cite.
It is not about keyword density, or word count targets, or any of the mechanical signals that traditional on-page SEO has trained writers to optimise for. AI systems do not rank pages in a list for someone to scroll through. They construct an answer by drawing on content they can retrieve, interpret, and confidently attribute.
The question an AI system is implicitly asking when it retrieves a page is: is there something here I can use to answer this query well? Content that answers that question is content that earns AI citation. Content that cannot be easily extracted, clearly attributed, or confidently summarised does not earn it, regardless of how well the site ranks on Google.
There is an important distinction between AI and traditional search worth holding in mind. A search engine returns a list; the reader decides what is useful. An AI returns an answer; the system decides what is useful. The bar for being the source an AI draws from is different, and in some ways higher, than the bar for ranking on page one.
| SEO Optimisation | AI Content Optimisation |
|---|---|
| Rank on a results page | Be the source an AI cites in its answer |
| Optimise for keyword presence | Optimise for confident extractability |
| Build links to increase authority | Build verifiable claims and attributed expertise |
| Match search intent with content | Match the question an AI system needs to answer |
| Long content often outranks short content | Clarity and specificity outperform length |
| Title and H1 alignment signal relevance | Citable definitions and named observations signal value |
The Foundation: E-E-A-T in the AI Era
Google introduced E-A-T (Expertise, Authoritativeness, Trustworthiness) as a quality evaluation framework in 2014. In December 2022, the framework was expanded with a second E: Experience, reflecting the growing importance of firsthand involvement as a distinct quality signal. The full framework is E-E-A-T: Experience, Expertise, Authoritativeness, and Trustworthiness. Google's own Quality Rater Guidelines, last updated September 2025, are explicit that Trust is the most important member of the group.
What has changed in 2026 is how directly these signals affect AI citation, not just traditional rankings. AI systems drawing on content to form an answer are effectively doing the same evaluation that human quality raters apply to search results. They are asking: can I trust this source enough to attribute an answer to it? Is this based on genuine expertise or generic synthesis? Is the author or organisation identifiable and credible?
Content that demonstrates strong E-E-A-T signals is not just more likely to rank. It is more likely to be the source an AI chooses to cite over alternatives that are technically accessible but harder to verify or attribute.
One pattern worth noting: the Experience pillar, the most recent addition to the framework, is increasingly the differentiator between AI-cited content and AI-ignored content. Original observations, specific examples from practice, named findings, and concrete scenarios all signal firsthand engagement with a topic. Generic summaries of well-known information do not. In a web increasingly saturated with AI-generated paraphrases of existing content, the presence of genuine first-hand experience is one of the clearest signals of value.
What AI Systems Are Actually Looking For: The Information Gain Principle
In 2018, Google filed a patent titled "Contextual Estimation of Link Information Gain" (Patent ID: US20200349181A1, granted 2022). The patent describes a scoring mechanism that evaluates how much new information a document provides relative to what a user has already encountered. Content that adds nothing the reader has not already seen scores low. Content that introduces a new angle, a named finding, a specific observation, or an original example scores high. (Source: Google Patents, US20200349181A1)
This principle matters for AI content optimisation because it describes exactly what AI systems are evaluating when they decide whether to cite a source. The relevant question is not "does this page cover the topic?" Almost every page covering a popular topic passes that bar. The relevant question is "does this page add something that other pages on this topic do not?"
In practice, information gain comes from specificity. A named observation from an audit. A concrete finding with a number attached. A scenario that illustrates a pattern in a way the reader has not encountered before. A definition that is more precise than the generic versions available elsewhere.
The inverse of this is worth noting too. Content that is well-written, well-structured, and comprehensive, but which adds nothing to what already exists on a topic, is increasingly likely to be ignored or paraphrased into the background. It passes basic quality filters. It does not earn citation.

The Five Signals AI-Optimised Content Needs
- A citable definition in the opening. The first section of a piece of content is disproportionately important for AI systems. It is where retrieval systems look first when identifying what a page is about, and it is the section most likely to be extracted when an AI system needs a concise definition to anchor its answer. A citable definition is precise, standalone, and written in a form that can be quoted or paraphrased without losing its meaning.
- Named observations and specific findings. Practitioners do not write in generalities. They write about what they noticed, what surprised them, what the data showed, what the exception was. These named observations are exactly what AI systems look for when distinguishing between a summary of existing knowledge (low information gain) and a source with something original to offer (high information gain). "Many websites have outdated robots.txt files" is a generality. "In the cohort we reviewed, 44.6% of sites with sitemaps returned a redirect when the sitemap URL was accessed" is a named finding. One is forgettable. The other is citable.
- Clear heading hierarchy with descriptive H2s and H3s. AI systems do not read pages the way humans do. They process structure as signal. A page where every H2 is a descriptive, question-answering heading gives a retrieval system a roadmap. Descriptive headings also make content more likely to appear in the specific answer format AI platforms prefer.
- Verifiable claims and attributed statements. Trustworthiness, the cornerstone of E-E-A-T according to Google's own guidelines, is demonstrated through verifiability. Claims supported by named sources, dated data, and linked references are easier for AI systems to trust and attribute than unsupported assertions, even when both say the same thing.
- Author and organisational identity. Content that cannot be attributed to a credible author or organisation is harder for AI systems to trust. Author schema, a visible and detailed author bio, credentials relevant to the topic, and links between the author's identity and their body of work are all signals that help an AI system answer: who created this, and should I trust it?
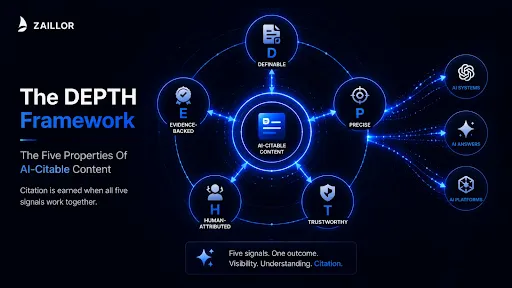
The DEPTH Framework by Zaillor
The five properties every piece of content must demonstrate to earn AI citation: Definable, Evidence-backed, Precise, Trustworthy, Human-attributed.
- D: Definable
- Opens with a clear, standalone definition of the core concept. A citable first paragraph that can be extracted without losing its meaning.
- E: Evidence-backed
- Claims are supported by named sources, dated data, or original findings. Assertions without attribution invite AI systems to hedge or skip.
- P: Precise
- Named observations and specific findings over generic statements. The more specific the claim, the higher the information gain score.
- T: Trustworthy
- Consistent with E-E-A-T signals: accurate, transparent about who created it, linked to verifiable sources, and free of unsupported assertions.
- H: Human-attributed
- Author identity and organisational context are visible, credentialed, and entity-linked. Attribution is what converts retrieval into citation.
To cite this framework: Zaillor (2026). The DEPTH Framework for AI Content Optimisation. zaillor.com
The Patterns That Most Content Gets Wrong
Generic openings that define nothing. The single most common content failure for AI citation is an opening paragraph that fails to define anything. "In today's rapidly changing digital landscape, businesses are facing new challenges..." is the most common opening sentence pattern on the web, and it is useless to an AI system looking for a citable definition. The opening of a piece of content is the highest-value real estate for AI citation.
Unsupported assertions stated as fact. Content built around assertions that sound confident but have no supporting evidence is a trust problem. "Our platform delivers 10x results" with no source or methodology. "Experts agree that..." with no named expert. AI systems are increasingly trained to be cautious about these patterns, because parroting an unsupported claim to a user carries reputational risk.
Thin content with high keyword presence. A page can satisfy a keyword match while offering almost nothing that an AI system would consider worth citing. Short pages with high repetition of keyword phrases, minimal explanatory depth, and no original observation are exactly what Google's Information Gain scoring is designed to discount.
Content that could have been written without any subject-matter knowledge. One useful test: could this content have been produced by someone with no real experience of the topic, using only a few hours of web research? If the answer is yes, it is unlikely to demonstrate Experience in the E-E-A-T sense, and it is unlikely to contain the kind of named, specific observations that generate information gain.
The AI content challenge is not that AI-generated content is inherently bad. It is that content generated without genuine subject-matter input tends to produce high-quality-looking paraphrases of existing knowledge with no information gain. Adding something requires knowing something.
Zaillor 2026 AI Content Optimisation Review: Common Findings
| Content Issue | AI Visibility Consequence |
|---|---|
| Generic opening paragraphs | AI systems find no citable definition |
| Claims without sources | Lower citation confidence |
| No author bio or author schema | Weak attribution signal |
| Long content with low originality | Low information gain |
| Weak heading hierarchy | Harder extraction and retrieval |
| No named observations | Content gets paraphrased instead of cited |
| No FAQ section | Fewer answer-ready extraction points |
Across Zaillor's AI Visibility reviews, the recurring pattern is not that businesses lack content. It is that much of the content does not contain enough definition, evidence, specificity, attribution, or original information to be safely cited by AI systems.
What This Looks Like in Practice
Scenario A: The Invisible Expert. A law firm specialising in employment contracts has a team of partners with decades of combined experience. Their blog covers every relevant topic in detail. But every post opens with a generic paragraph about the importance of the topic, defines concepts in the same broad terms available on Wikipedia, and makes claims without linking to any source. When someone asks an AI assistant about employment contract enforceability clauses, the AI cites a much smaller firm whose blog is more specific, includes a named case pattern from the author's practice, and quotes a relevant statute. The larger firm's blog ranks well. It just does not get cited. Result: Technical depth and genuine expertise are invisible to AI systems when the content does not surface named observations, specific examples, or attributed claims.
Scenario B: The Specific Observation. A logistics software company publishes a post about route optimisation. The post opens with a precise definition. It includes a named finding from their implementation data: the specific percentage reduction in delivery time observed across a cohort of clients. The author bio links to the author's LinkedIn profile and their company's structured data. When someone asks an AI assistant about software approaches to last-mile delivery efficiency, this post is cited directly. Result: One specific, attributed, named finding in an otherwise normal blog post is enough to differentiate it from dozens of similar pieces covering the same ground.
Scenario C: The Trustworthiness Gap. A healthcare information website publishes a detailed, accurate, well-structured post about a common medication interaction. The content is correct and written by a qualified pharmacist. But the site has no visible author bio, no author schema, no Organisation schema, and no links to the regulatory guidance documents it references. When an AI assistant draws on sources for an answer, it prioritises a less detailed post from a site with clear author credentials and cited sources. Result: Content quality and trustworthiness signals are not the same thing. An AI system with multiple options will choose the one it can most confidently attribute.
What You Should Do Now
Step 1: Audit your content for extractability. Go through your highest-traffic and most commercially important pages with one question in mind: if an AI system retrieved this page, what would it extract? Is there a clear, citable definition in the opening? Are there named findings or specific observations that would stand out against competitor content on the same topic? Are claims supported by named, linked sources? Zaillor's AI visibility audits assess content optimisation as the fifth and final parameter, sitting on top of crawlability, sitemap structure, structured data, and entity clarity.
Step 2: Fix the opening paragraphs first. If there is one change that consistently improves AI citation rates more than any other content change, it is rewriting generic opening paragraphs into precise, citable definitions. The opening of a page is where retrieval systems look first. A precise opening does not need to be long. It needs to be specific enough to stand alone as the answer to the question the page is about.
Step 3: Add attributed specificity to existing content. Most content can be improved for AI citation without a complete rewrite. Identify the two or three claims on each page that matter most for the topic. Add a named source, a dated statistic, or a specific example from practice to each one. Name the observation rather than leaving it implied. These targeted additions often change the information gain profile of a page significantly.
Frequently Asked Questions
- Is AI content optimisation the same as SEO?
- They overlap significantly but are not identical. Traditional SEO optimises for how a page ranks in a list of results that a human reader then evaluates. AI content optimisation focuses on whether the content gives an AI system something it can confidently extract, summarise, and attribute in a direct answer. The signals that matter for AI citation — named observations, citable definitions, attributed claims, clear heading structure, and E-E-A-T signals — are all consistent with good SEO practice. But the goal is different: being the source an AI chooses to cite, not the result a user chooses to click.
- Does E-E-A-T apply if I am not a health or finance site?
- Yes, though its weight varies by topic. Google's guidelines define Your Money or Your Life (YMYL) topics as those where inaccurate information can cause real harm, and apply stricter E-E-A-T requirements there. But E-E-A-T signals matter across all topics for AI citation, because AI systems make trust decisions regardless of subject matter. The standards differ in consequence, not in principle.
- What is the DEPTH Framework by Zaillor?
- The DEPTH Framework by Zaillor is a model for creating AI-citable content. DEPTH stands for Definable, Evidence-backed, Precise, Trustworthy, and Human-attributed. These five properties help content become easier for AI systems to understand, extract, verify, and cite.
- Why can a page rank on Google but still not get cited by AI systems?
- A page can rank because it is relevant, crawlable, and authoritative enough for search, but still fail to earn AI citation if it lacks extractable definitions, original information, attributed claims, or visible author credibility. AI systems need content they can confidently use in an answer, not just content that matches a query.
- What is Information Gain and why does it matter?
- Information Gain is a concept from a Google patent (US20200349181A1, granted 2022) that describes evaluating a document by how much new information it provides relative to what a user has already encountered. A page that covers the same ground as every other page on the topic has low information gain. A page that introduces a named finding, a specific observation, or a concrete example not found elsewhere has higher information gain. AI systems are more likely to cite sources that add something to the conversation than sources that summarise it.
- Can AI-generated content be AI-optimised?
- The origin of the content is less relevant than whether it demonstrates genuine expertise and information gain. Content generated with AI assistance but grounded in original findings, real data, subject-matter input from practitioners, and attributed claims can demonstrate strong E-E-A-T signals. Content generated purely from existing web sources, without adding any original angle or named finding, will tend to produce low information gain regardless of how well-written it is.
- How does content optimisation connect to the rest of the Zaillor audit?
- Content optimisation is the fifth parameter in the Zaillor AI Visibility Audit. The other four parameters determine whether AI systems can reach your content and understand your identity. This fifth parameter determines what they find when they arrive. A site with perfect crawlability, a clean sitemap, rich structured data, and strong entity clarity still fails to earn AI citation if its content gives AI systems nothing worth extracting. The five parameters work as a connected system.
- What does Zaillor assess in the content optimisation parameter of its audit?
- Zaillor's content optimisation review looks at whether core pages open with a citable definition, whether claims are attributed to named sources, whether heading structure supports extraction, whether author identity and credentials are visible and schema-marked, and whether the content demonstrates original observations or findings rather than generic synthesis. The assessment is done alongside the other four parameters — structured data, robots.txt, sitemap, and entity clarity — in the Zaillor Website AI Audit.
The Bottom Line
Getting crawled and indexed is the floor, not the ceiling, of AI visibility. The first four parameters in the Zaillor audit — structured data, robots.txt, sitemap structure, and entity clarity — deal with the floor. This fifth parameter is what determines what happens once AI systems are above it.
A site that is technically impeccable but produces generic, unattributed, undifferentiated content will earn crawl access and nothing else. AI systems will retrieve the pages, find nothing worth citing that they could not find ten places elsewhere, and move on.
The E-E-A-T framework and the Information Gain principle describe the same thing from two angles. Together they point to the same conclusion: the content that earns AI citation is content that adds something. A specific finding. A named observation. A citable definition. A claim supported by a named source. An author whose identity and credentials are visible and verifiable.
None of this requires long content, elaborate formatting, or a team of specialist writers. It requires knowing something, saying it specifically, and making it easy to attribute. That has always been the standard for good writing. It is now also the standard for AI-visible content.
This is where the series ends. Five parameters, one connected system. Structured data tells AI systems what your content means. robots.txt determines which systems can access it. The sitemap tells them what to prioritise and how fresh it is. Entity clarity establishes that they are dealing with one consistent, verifiable thing. And content optimisation determines whether what they find is worth citing.
The Zaillor audit assesses all five in a single review, producing a score and a prioritised list of what to fix first. Most of the changes that improve AI visibility are not large technical projects. They are specific, targeted adjustments to things that are already there but not yet working as well as they could.